RailsのActive Recordのmysqlでマイクロ秒を切り捨てる方法
mysqlでマイクロ秒まで計算してくれるのは嬉しいのですが、保存されるときには切り捨てにされています。
Railsのend_of_dayを使うと、.9999になります。
where('start_at <= ? and end_at >= ?', date.beginning_of_day, date.end_of_day) SELECT `xxxx`.* FROM `campaigns` WHERE (start_at <= '2019-09-28 15:00:00' and end_at >= '2019-09-29 14:59:59.999999') LIMIT 11
ギリギリまでそれを加えたいのに、加わらないというジレンマが発生します。
この回避方法です。
文字列にします
where('start_at <= ? and end_at >= ?', date.beginning_of_day, date.end_of_day.getutc.to_s) SELECT `xxx`.* FROM `campaigns` WHERE (start_at <= '2019-09-28 15:00:00' and end_at >= '2019-09-29 14:59:59 UTC') ORDER BY `campaigns`.`id` ASC LIMIT 1 OFFSET 1
もっといいやり方あると思うので、何かいい方法を知っている方は教えてください!
参考
cronのログを設定する
debianを使っているのですが、デフォルトだとcronのログが出力されません。(デフォルトで表示してくれ!)
なので、cronのログが出るように設定します。
/etc/rsyslog.conf
# cron.* /var/log/cron.log ←コメント外す
この後にrsyslogを再起動します。
sudo /etc/init.d/rsyslog restart
以上です。
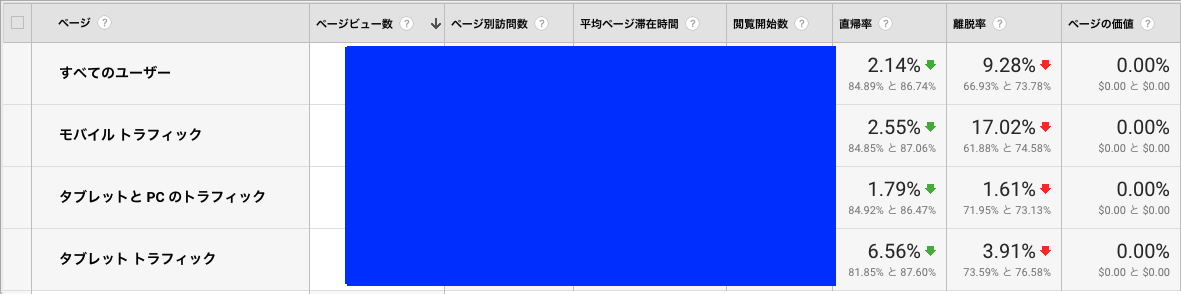
フォントサイズを1px変更するだけで、直帰率が2%前後下がった
タイトルの通りです。
こんな効果あるのか?と思い、正直ビックリしました。
期間は6/4~6/6(比較は5/28~5/30)
運営しているサイトはbookwithという読書管理サイトです。
きっかけは、サルワカさんのサルワカという個人メディアを250万PV/月にまで育てた方法の記事を見たことです。
「おしゃれ」よりも「快適に過ごせること」
Webメディアにとって、デザインは重要な要素だ。しかし、デザインを設計するときには、「おしゃれさ」を優先してユーザービリティを損なうことがないように気をつけなければならない。ユーザーからすると「おしゃれに見えるかどうか」よりも「快適に過ごせること」の方が重要なのだ。
これを見て、かっこつけてフォント小さくしすぎていないか?と思いました。
ユーザーが読みやすいサイトの方が居心地はいいはずだと。
そう思い、文字サイズを変更することで読みやすくなるのでは?と考えました。
ただ、急に大きくしすぎても微妙なので、1pxだけにしました。
そうすると、上の画面の結果になりました。
文字サイズだけでここまで影響あるのか・・・と感動しました。
読みやすさは大事ですね。
「続きを読む」ボタンの文章の高さを可変的にしてボタンを設置する方法
「続きを読む」ボタンの情報を探していましたが、どうも高さが固定前提です。
下記のようなやつです。
------- 表示する文章←ここの高さ固定 「続きを読む」ボタン 隠す文章 -------
ただ、自分はその文章の量が変動かつ、さらに少ない場合もあります。
なので、文章サイズの量は固定できません。
ここで一旦いつもの実装パターンを確認します。
実装方針
- 隠す文章を
overflow: hiddenする - 表示する文章のcssの
heightで決めておく - 「続きを読む」ボタンを
jQueryで表示する文章の兄弟要素に加える - 「続きを読む」ボタンクリックで、隠す文章の
overflow: hiddenを解除する
やり方
自分のケースは、文章が固定じゃないので、サイト表示後に高さを取得すればいいです。
それだけです。
実装方針
- 文章の高さを取得する
- 想定している高さ以上の場合は、文章を隠す。(overflow: hiddenを加える)
- 隠す文章の兄弟要素の下にDOM(ボタン)を作成する
- クリックすると表示するイベントを仕込む
作ったjsがこれです。
export default class Readmore { constructor(targets, element, height, cssList, text) { this.targets = document.querySelectorAll(targets) this.element = element this.height = height this.cssList = cssList this.text = text } more() { this._hidden() this._createButton() } _createButton() { const self = this this.targets.forEach((target) => { const height = target.clientHeight if (height == self.height) { const element = document.createElement(self.element) self.cssList.forEach((klass) => { element.classList.add(klass) }) element.innerHTML = self.text target.parentNode.insertBefore(element, target.nextSibling) const button = target.nextSibling button.addEventListener('click', () => { self._show(target) button.parentNode.removeChild(button) }) } }) } _hidden() { const self = this this.targets.forEach((target) => { const height = target.clientHeight if (height > self.height) { const style = target.style style.overflow = "hidden" style.maxHeight = `${self.height}px` } }) } _show(target) { const style = target.style style.overflow = "" style.maxHeight = null } }
import readMore from '../../lib/utils/readmore.js' const targets = ".foo" const element = "button" const height = 100 const cssList = ["bar", "baz"] const text = "続きを見る" const ReadMore = new readMore(targets, element, height, cssList, text) ReadMore.more()
targetsっていう変数に対象となる場所を入れます。
文章の高さも可変的にしました。
他でも流用できそうな部分は変数で渡すようにしました。
これだと、他の場所でも使えるのではないでしょうか。
もっといい書き方やスマートなやり方があると思うので、いい方法があればぜひ教えてくださいm( )m
「エンジニアのための図解思考 再入門講座」を読んだ
図解で物事を理解する経験を何度も繰り返してきた。
その割には、自分が図解して説明することができなかった。
なぜなら、図解するには物事がどういう構造になっているかのかを理解しないと説明できないからだ。
図解する行為自体は興味があり、そんな折に翔泳社セールで半額になっていたこの本を見つけた時に、僕は買わずにいられなかった。(半額じゃなかったら、買わなかったかもしれないというのは置いといて)
この本では、著者が生徒に図解する方法論を唱えても理解してもらえなかった経験があり、具体的にどのようにして図解するかのアプローチが書かれている。 練習問題もあり、実践的な内容になっている。

- 作者: 開米瑞浩
- 出版社/メーカー: 翔泳社
- 発売日: 2013/08/09
- メディア: Kindle版
- この商品を含むブログを見る
僕が印象に残ったのは、次の3つです。
- ラベルをつける
- 表をつける
- 未知の問題に対処する
それについては説明します。
他にも有用な章ばかりなので、気になる方は読んで見てください。
ただ、残念なのは、現在は翔泳社セールはないということだ。
ラベルをつける
ラベルをつけるという行為は一体どういうことなのか?
よく僕は何かをプログラミングを作る時に箇条書きで何をやるかを書く。
とりあえず、情報を集めて、整理したいからだ。
ただ、これだけではなく、情報をきちんと整理して伝えろという。
例えば、twitterの特徴を次の3行にまとめました。
- 140文字の制限で情報を即座に発信する
- 情報を他者に広めることができる
- 情報を発信する人の購読ができる
これにラベルをつけます
- 【速報性】140文字の制限で情報を発信する
- 【拡散】情報を他者に広めることができる
- 【情報収集】情報を発信する人の購読ができる
特徴が浮き彫りになった気がしませんか?
ラベルをつけることによって情報を浮き彫りにすることが、まずは大事です。
カテゴリー分けをしないと、図解して、表にしようにも分類ができないからです。
表をつける
そんなの当たり前じゃないか!と思います。
各SNSでの特徴を教えてください!と言われた場合は、どのようにして説明しますか?
ここで先程のラベルが役立ちます。
| SNS | 速報性 | 拡散 | 情報収集 |
|---|---|---|---|
| ◯ | ◯ | ◯ | |
| ✖️ | △ | △ |
これだとinstagramが涙目じゃないか?って感じます。
涙目のクセになぜ流行るのかという話になります。
未知の問題に対処する
表を作ることで、疑問も生まれました。
では、ここでinstagramの特徴を調べました。
- 【ビジュアル情報】写真に特化した情報
- 【美しい世界観】綺麗な写真しかない
- 【タグ付け文化】情報はタグ検索で取得する
どちらかというと、文化要素が強いのかなって思います。
文化面
| SNS | ビジュアル情報 | 美しい世界観 | タグ付け文化 |
|---|---|---|---|
| △ | ✖️ | ◯ | |
| ◯ | ◯ | ◯ |
ということは、instagramの利用者は情報収集性を求めてはおらず、世界観が好きで利用しているということが推測できます。
ちょっと強引な感じがしますが、情報をラベルで整理しないとカテゴリーがわかりません。
感想
実際には、もっとわかりやすい説明が書いてあるので、興味がある方はぜひ読んでみてください。
興味深い話は、情報から出来事を想像できない人が増えているということです。
これは自分もそうなのですが、わかりやすい教材のおかげで、自分で試行錯誤する機会が減っているのでは?という推測が書かれています。
情報を整理して、わからない部分を試すことで、理解が深まります。
その部分が一番大事だと強調しています。
わからないことを知る気持ちが大切ですね。
書誌情報を取得するAPI(openBD)のラッパーのgemを作成した
個人で読書管理サイトを作成しており、書誌の情報が欲しいと思い、利用できる場所を探していた時に出会いました。
調べたところ、goのライブラリはあったのですが、ruby用がなかったので作成しました。
isbnを送信するだけで、結果が返ってくるので楽です。
あとは、その結果を利用しやすいようにラッパーを作成しました。(title/contributorsなどで値を取得したかった)
ライブラリの使い方
READMEから抜粋しました。
client = OpenBD::Client.new # Pass the value of isbn to isbns res = client.search(isbns: []) res.empty? res.body res.status # [OpenBD::Resource] res.resources.each do |resource| res.content res.content_detail res.contributors # [OpenBD::Contributor] res.cover_image res.height res.isbn res.main_title res.paper_size res.paper_size_detail res.publisher res.release_date res.sub_title res.table_of_contents res.title res.width end
こんな素晴らしいデータを自由に利用させてくれるなんて、感謝しかない。
webのスマホサイトとアプリのUIの壁
webのスマホサイトも段々アプリのようなUIをする動きが増えてきました。
ユーザーからしてみると、普段はアプリを利用しているので、できるだけアプリの動きに近い方が馴染みやすいです。
アプリのようなUIに合わせるのは当たり前の流れなのかもしれません。
下は自分がツイートしたものですが、検索UIにおいては、上部にそのまま検索できるようにしておくことが増えてきました。
スマホサイトの検索結果上部に検索結果を変更できるようなUI最近増えてる。
— mikami (@sukechansan) 2018年1月28日
地の人から借りる家、体験&スポット - Airbnb https://t.co/Bwv7eUVizP https://t.co/Gux7v9hoFt pic.twitter.com/CiQbFkT8Zd
しかし、どうしても真似をすることのできない壁があります。
webのスマホサイトは検索からくる人を想定しないといけません
これがどこに影響してくるのかです。
- サイト名
- SEOを意識したワード表示
主にこの二つかなと思います。
これは大体のサイトにおいてファーストビューの上部に表示されます。
前者については、どんなサイトかわからないので、必然的に表示することになります。
後者については、google先生にどんなページかを伝えないといけないため、どうしてもSEOワードになりがちです。
ファーストビューで見せないといけない情報になるので、アプリだとその二つを削れるってのは大きい気がします。
食べログの例
食べログで二つの差を見てます。
スマホサイトは「渋谷駅 ランチ」で検索した結果を表示しています。
アプリは位置を「渋谷駅」と営業時間を「ランチ」で条件検索しました。
スマホサイト

アプリ

アプリだと、タイトルはいらないので、削って代わりに並び順を意識させています。
また、SEOを意識した表示しなくていいので、「グルメ・レストラン」というワードを削り、表示箇所を分けています。
アプリはサイト内にいる前提で作成できる
完全にユーザーにとって必要な情報だけを渡すことができます。
なので使い勝手を追求した作りにするのがベターだと思います。
webスマホサイトの場合は、UIはできるだけアプリに近づけつつ、SEOを意識した作りになるので、どうしても使い勝手では不利になります。
ただ、この話の前提は検索結果で来るサイトならではの話なので、webでも完全に閉じた世界(検索いらないサイト)で行動できるなら、思い切った見せ方をしてもいいかもしれないですね。
Intersection Observerを使ってみた
JavaScriptのIntersection Observerが便利じゃないのか?と気づき、ちょっと利用しました。
Intersection Observerとは
直訳すると、「交差点の監視」という意味でしょうか。
Intersection Observerの何が便利かというと、対象物が画面に入る時に処理を実行することができます。
この辺の処理はスクロールイベントで頑張ることが多かったのではないでしょうか?
そこが楽になります。
できることとして、例によく出るのですが、
- 画像の遅延読み込み
- 無限スクロール
の実装が楽になります。
なぜなら、これ系の処理は画面に入るまでは実行しなくてもいいからです。
今まではライブラリに頼ることが多かったと思いますが、自前でも簡単に作ることができます。
画像の遅延読み込みのライブラリで、layzr.jsはIntersection Observerを利用して、コード数を削減しています。
実装のサンプルコードとして、Vueで無限スクロールを実装したコードを置いておきます。
余談
この作者のライブラリには、他にもIntersection Observerを利用しているので、好きなのか、便利さにはまっているのかなって気持ちになりました。
使い方
const io = new IntersectionObserver((entries) => { for (let entry of entries) { console.log(entry); } }); io.observe(target);
これでターゲットが画面に表示するかどうかで判定処理が動きます。
実装のサンプルコード
検索結果の無限スクロールです。
loadingとかはないので、形だけです。
export default class SearchScroll { constructor(list) { this.list = list this.page = 2 const parser = document.createElement('a') parser.href = location.href this.parser = parser } path() { const params = { page: this.page } const query = $.param(params) return `${this.parser.pathname}.json${this.parser.search}&${query}` } target() { return this.list.children[this.list.children.length - 1] } }
import axios from 'axios' import SearchScroll from './search_scroll.js' mounted() { const self = this const list = document.querySelectorAll(`[data-sentinel]`)[0]) const searchScroll = new SearchScroll(list) const sentinelListener = (entries) => { const entry = entries[0] if(entry.intersectionRatio > 0) { io.unobserve(entry.target)←対象に入ったら前の監視をやめる axios.get(searchScroll.path(), { headers: { 'Content-Type': 'application/json' } }) .then((response) => { searchScroll.page += 1 self.lists.push(...response.data) io.observe(searchScroll.target())←新しい監視を始める console.log("success") }) .catch((error) => { console.log("fail") }) } } const io = new IntersectionObserver(sentinelListener) io.observe(searchScroll.target()) }
感想
画面に表示しているかどうかってのいうのは、今後フロントエンドで処理をする上で何かで使いそうなので、覚えておきたい。
細かい制御もできるので、その辺の理解をきちんとしたい。
参考
JavaScriptのdebuggerでデバッグが楽になる
やっとconsole.logから脱出できそうな気がしてきました。
今までずっとconsole.logを利用してきました。
これからも使っていくでしょう。
ただし、debuggerの存在に気づいたので、debuggerを利用していきたいと思います。
何がいいかっていうと、実行時にブレイクポイントで止まってくれる。
これに尽きます。
利用方法
document.addEventListener('DOMContentLoaded', () => { document.getElementById("foo").addEventListener('click', () => { debugger←差し込む }) });
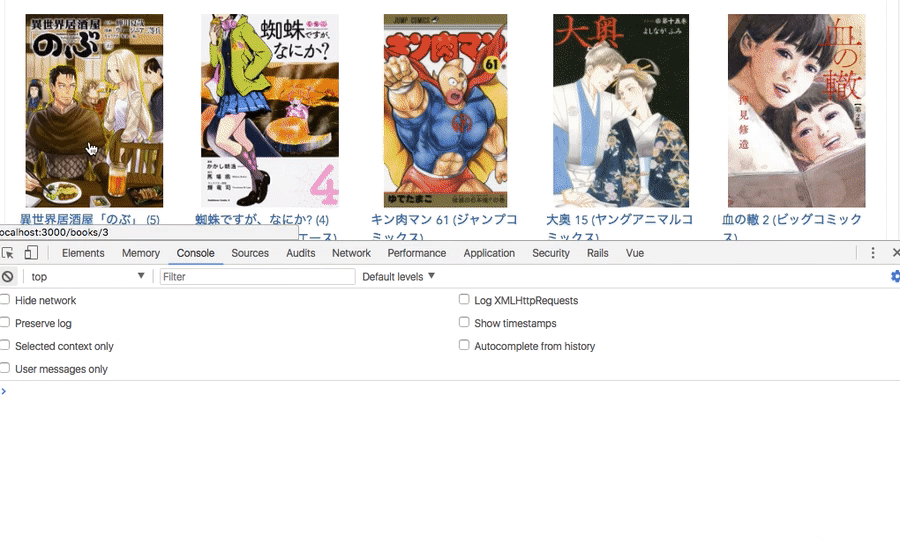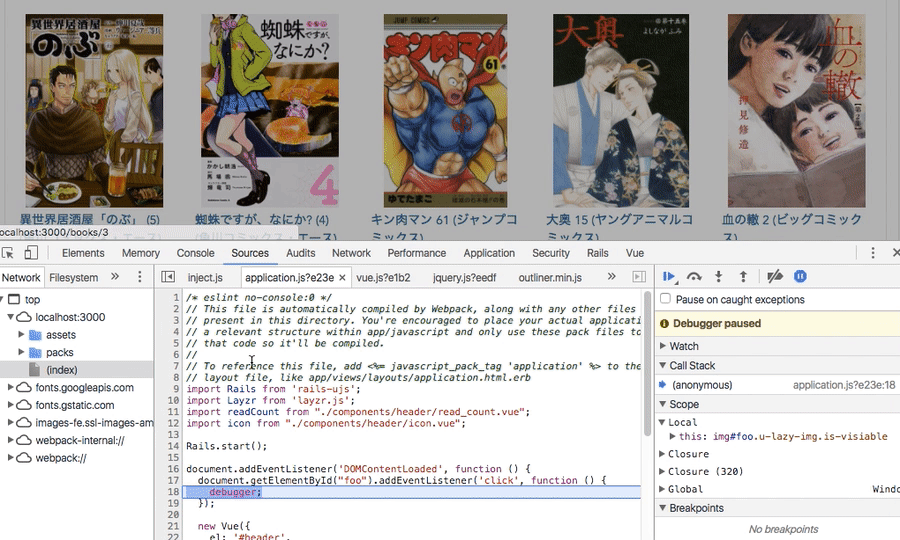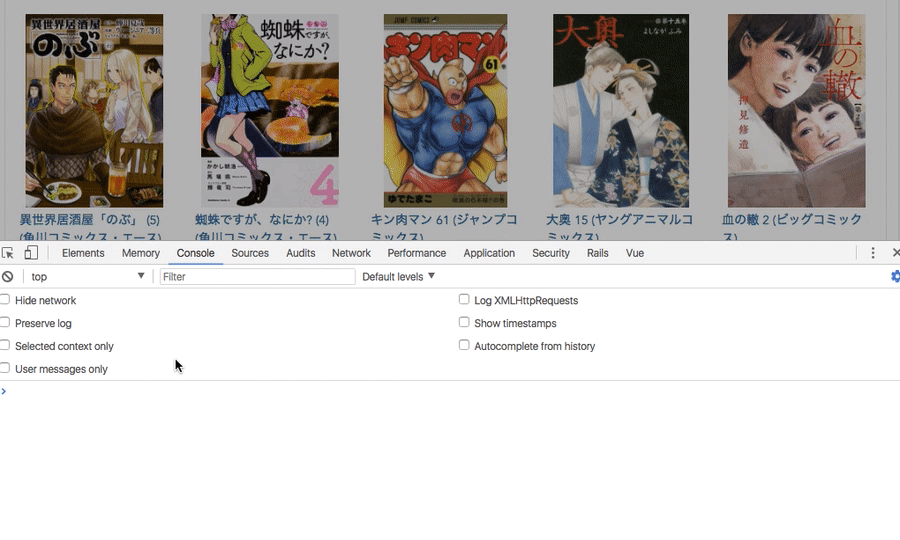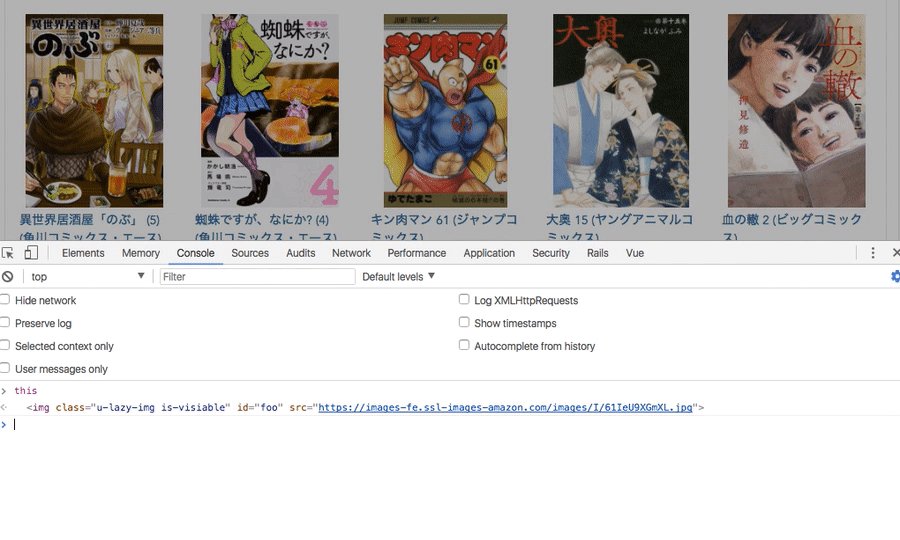
上の画像でクリックすると、差した場所でブレイクポイントで止まっていると思います。
これが便利ですね。
これで少しは楽になりそう。
インターフェースデザインの心理学を読んだ
デザインによって、人は使いやすいかどうかを判断するので、役に立つかなと思い読んでみました。
正直内容が心理学的の話をしており、インタフェースの話(ホームページのデザイン)じゃないの?って思ったのが正直な感想です。
微妙に騙されたな・・・って思ったのですが、印象に残っている話があります。
データより物語の方が説得力があると言う話です。
インズタグラムもストーリーっていう機能をリリースしたし、妙に印象に残ったんですよね。
データの提示だけでは感情に訴えづらい
子持ち世帯が中古マンションを購入しようとします。
条件は人それぞれですので、簡単なデータだけにします。
- 中古マンションを購入した人の80%は満足
- 満足した理由の一位は子供が喜んでいる
これだけのデータでも購入する人はすると思います。
つっこみどころは置いといてくださいw
では、自分の信頼する人が中古マンションを買った時のよかった感想を伝えてきたらどうなりますか?
あの人が言うのなら・・・っていう感情は出てくるのではないでしょうか。
データより物語に説得力がある理由
本に書いてある理由です。
- 物語は感情的に訴える力が強い
- 物語は聞き手の共感を呼び、それにより情緒的な反応をする
- 感情は記憶中枢にも働きかける
要するに、印象に残るってことですね。
最近は動画でものを紹介することが増えていますね
- youtuberの宣伝動画
- メルカリチャンネル
youtuberの宣伝動画なんて、企業からお金もらっていることが多いから、宣伝の方が多いでしょう。
そんなことさておいて、youtuberの人が楽しく、便利なことを紹介してきたら、親近感があるので購入すると思います。
そもそも、宣伝動画なんていうフィルターをかけるのは、業界の人だけでしょう。
感想
僕はブログでもストーリー性がある話は好きです。
それは、感情に訴えてくる部分があるからでしょう。
ストーリー性をうまく持たせる機能を作ることができたら、ソーシャルで広まりそうなサービスが生まれる気はしています。
ただ、難しいのは、それをユーザー側にやってもらうことです。
動画は自然に登場人物が出てくくるので、ユーザー側でもできやすいのかなって思ったりしています。
ストーリーは何かにうまく組み込みたいなって感じています。
以上。

インタフェースデザインの心理学 ―ウェブやアプリに新たな視点をもたらす100の指針
- 作者: Susan Weinschenk,武舎広幸,武舎るみ,阿部和也
- 出版社/メーカー: オライリージャパン
- 発売日: 2012/07/14
- メディア: 大型本
- 購入: 36人 クリック: 751回
- この商品を含むブログ (31件) を見る